Formulas & proofs for the Log-normal Distribution
Supporting formulas for the Log-normal Distribution Post
Obtaining the log-normal maximum likelihood estimators
We start with the likelihood function which is:
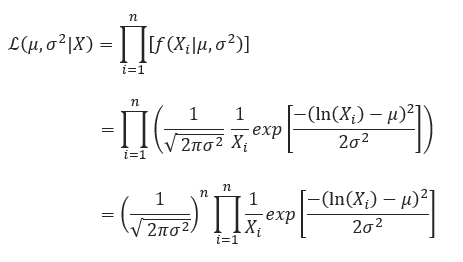
We then take the natural log of the likelihood function (helps simplify our calculations).

To find the μ and σ which maximise our log-likelihood function we take the gradient of our log-likelihood function with respect to μ and σ and set it to 0.

To prove that these two estimators maximise our log-likelihood function we confirm that the Hessian matrix is negative-definite. We won’t look into these steps here.
The mode is the value that maximises the probability density function (pdf). We, therefore, take the gradient with respect to x and set it equal to 0.

erf is the error function. The median is the value where the cumulative distribution function (cdf) is 0.5.
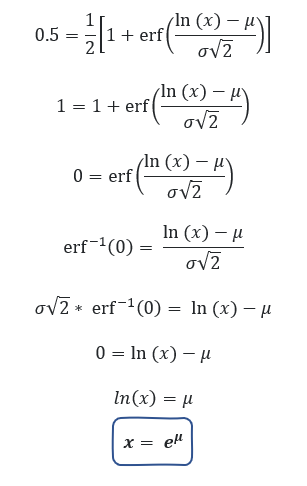
References:
[1] Wikipedia, Maximum Likelihood Estimation (2022), retrieved on 2022–02–06
[2] J. Soch, K. Petrykowski, T. Faulkenberry, The Book of Statistical Proofs (2021), github.io
[3] Mdoc, Mode of lognormal distribution (2022), retrieved on 2022–02–04, Mathematics Stack Exchange, URL (version: 2015–06–11)